MySQL Fabric
Note: It’s a long time since I used Fabric and wrote this as a draft, so take this as a warning that it may be dated in places. I did put a lot of effort into the diagrams though so I’m publishing it anyway 😀
MySQL Fabric is an official High Availability (HA)/Sharding/Load Balancing framework for MySQL databases. It’s great for managing replication with multiple slaves and makes it easy to set up read-slaves. It does have a few caveats, and can be a bit hairy in a Windows environment but overall, it’s not bad. The good news is that although there are binaries, they were written in Python so you can easily fix any bugs yourself 😉
You can download it as part of the MySQL Utilities package, or even clone it from GitHub.
Before getting into any details, here’s a quick diagram of a basic Fabric environment containing:
- 2 database nodes – one read/write, the other a replicated read slave
- 1 MySQL Fabric Controller node
- 1 Application using a Fabric-aware Connector
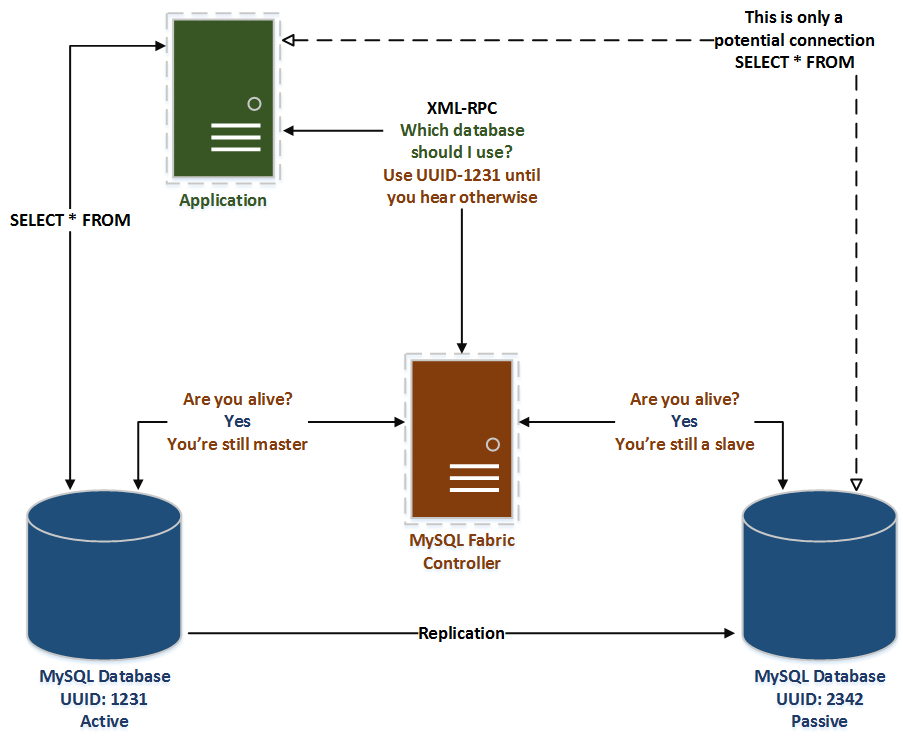
The Controller is not a Single Point of Failure
The official stance is that due to the Connector in the application having a cache, the Controllor is not a single point of failure. The Controller is the bit applications connect to, it’s the load balancer, the bit that manages replication, and the bit that decides when to failover to a slave. Basically, it’s the really important bit, and they only expect you to have one of them.
I’ve tried to demonstrate this argument in the diagram – the application doesn’t route requests through the Controller. The Controller (as far as the application is concerned) is just a way to identify what database to connect to, it then caches that information and may be capable of surviving the death of the Controller. It heavily depends on that application being well written and not creating new instances of the Connector regularly, but, it could very well be sufficient.
Have multiple Controllers anyway
Rather fantastically this is documented. It isn’t exactly light on resources but it works, and as far as my testing has been able to tell allows two Controllers to be run in parallel. The Fabric-aware Connector doesn’t support this, but it’s nothing a bit of extra code or a load balancer/firewall rule/DNS entry/application restart can’t handle.
The diagram for a more HA configuration using the MySQL Cluster technique is way more fun than that last one
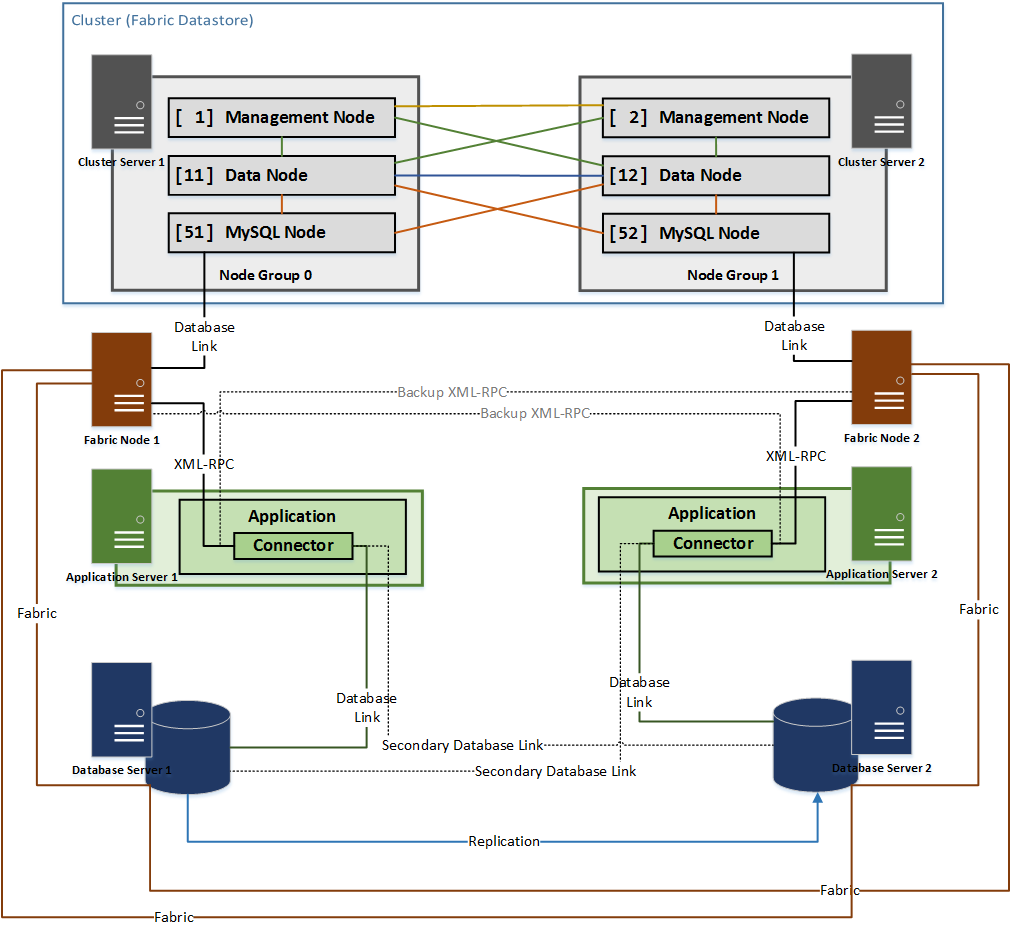
In short:
- Create a MySQL Cluster to use as a Fabric datastore
- Give it two entry points – this is supposed to be HA after all
- Move system user tables to a cluster storage engine
- Create two identical Controllers but point to different cluster entry points
- They are now sharing a datastore in a non-conflicting manner
- Create two standard MySQL databases
- Set up replication
- Add them into Fabric management
There’s a million things that could still go wrong, but it’s stable and gives far more options that having a single Controller does.
Odd things
Last I checked it wasn’t easy to create an auto-failover environment with a read/write master and a noread/nowrite slave. I hope that changes because sometimes you just don’t want to balance reads to a potentially stale database!